



Data is the key business differentiator. Mining of data or scraping the web for data is pivotal to the success of any promotion or marketing campaign. Be it a lead generation activity, a price mapping project or a reputation management effort, data is the driving force. Start-ups and Fortune 500 companies alike are vulnerable to the need for data to help take strategic business decisions.
Evolution of web scraping solutions
The need to parse data has been an established necessity, continuously evolving over time. Initial scraping solutions involved manual visiting of websites, copy-pasting the data and compiling it on spreadsheets- all on local systems. Evolution saw web scraping go through the initial manual process to using offline downloaders to programs which would automatically capture images from targeted URLs using OCR (Optical Character Recognition).
Big Data and Advanced Analytics gave web scraping techniques a transformational leap with Robotic Process Automation (RPA), Machine Learning (ML) and Artificial Intelligence (AI), web extraction techniques evolved to enhanced automated techniques like Robotic Process Automation (RPA), Machine Learning (ML) and Artificial Intelligence (AI) becoming the new buzz technologies.

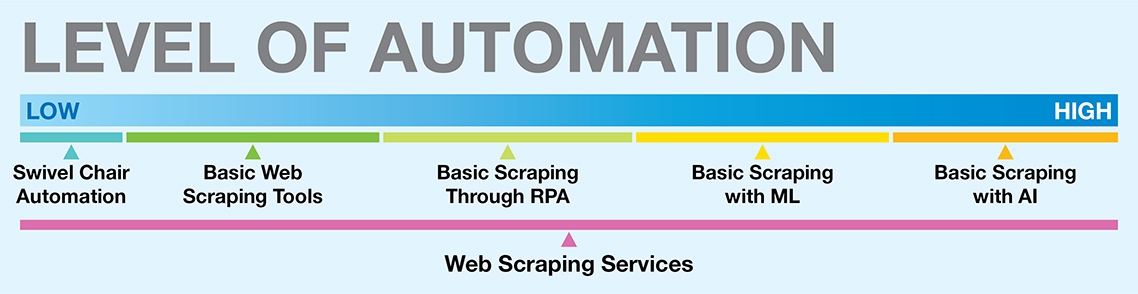
Innumerable web scraping services and solutions have flooded the market, each of varying scope and leveraging different technologies. All claim to be the best and maybe there is truth in most claims. But the important thing here to understand is that a service or solution is only as effective as its need. There is no one size fits all. Businesses need to understand their specific needs and stage of growth and map that to the solution they choose.
So what are factors to weigh in when choosing a web scraping solution?
Stage of businesslife-cycle
The stage of your company in the business life cycle is a critical factor in deciding the solution you should implement for data extraction. You need to ask yourself How significant is this data for the growth of my company today? At what interval do we need it? Can we justify the investment against the benefits?
Type and quantity of data to be scraped
This is by far the most important factor which should be given at least 50% weight in determining your web extraction solution. Extracting data comes across technical obstacles like captcha, anti-scraping bots, and structural changes which need to be considered while choosing the right solution. Extraction and conversion of voluminous data sets require employing sophisticated extraction techniques.
Potential for financial and manpower investment
While investing in a solution, the ROI should be analyzed to know if the investment is worth the return. An optimal solution needs to have a balance of the resources you have vs resources you can hire, all the while ensuring there is not much pressure on your financials.
Hardware and software infrastructure accessible
Creating an in-house web data extraction and analysis process would require you to have the necessary IT infrastructure (hardware and software). Moreover, the management of the whole process needs appropriate resources with programming and analytics knowledge to give you the required insight.
Scalability
As the business expands the need for data extraction also increases. Hence, whichever process is implemented for scraping should have the capability of scaling up or down based on the need of the business.
What are the types of web scraping solutions that one should consider?
Let us see some examples to understand how companies figure out which solutions suit them best for their data extraction requirements.
4 years ago, Liam Garcia from Texas, decided to launch his eCommerce website to sell original hand-painted T-shirts. He launched his website with a total of 10 products in his product basket. Soon he realized how competitive the eCommerce market was and the importance of web data extraction to gain competitive advantage.
But at this stage, all he needed was to extract prices and product information from eight competitor websites. So, in all data extraction for 80 products twice a day. Such a task can be easily completed by hiring a single data entry operator. The operator could just swivel around in his chair and give you the correct information every day, which brings us to Swivel Chair Automation.
Swivel chair automation (Manual data extraction)
Well, wait, this is not an automation process. It is just a term used to define the process of manually going through several systems and websites, copying and pasting the required information. Imagine a typical workplace in which a data operator works between different systems and monitors swiveling around copying and pasting data into a single file. Hence, the name.
For, the amount of data he needed at this point, manually collecting information was the right solution considering the time and cost investment required to implement any other scraping solutions.
Advantages of swivel chair automation:
- Cost-effective
- The structure or type of website does not matter
- No technical knowledge required.
Disadvantages of swivel chair automation:
- Reduced productivity
- Diminished Accuracy
- Waste of resource time
- Limited Scalability
- Incomplete Process Visibility and Analytics
Well, although perfect for that stage of the business cycle, it was not long before the solution wasn’t adequate. The collected data and resulting decisions increased the demand for his T-shirts resulting in:
- An opportunity to launch new products (trousers, jeans, accessories)
- New competitors emerged, targeting his customers.
- Need for more fast and precise data.
Hence, the manual scraping process which was working so perfectly, suddenly started to feel inefficient. It was time to move on to basic web scraping tools (already available in the market) to enhance the performance of extraction.
Basic web scraping tools (DIY tools)
Basic Web Scraping tools are DIY (Do-It-Yourself) tools that extract specific information from the URL provided by you. You can then make changes or corrections to the information they have extracted to match your requirements. These DIY tools are available for free or at economical prices and are a very good way to extract data from the web when the data to be extracted is too much to be done manually but manageable. The accuracy rate is better than Swivel Chairing and can save resource time which can be used in analyzing and finding insights from the resulting data.
Advantages of basic web scraping tools:
- Saves resource time
- Ultimately cost effective as it is scalable to some extent.
- Manageable within the business unit
Disadvantages of basic web scraping tools:
- Can’t access dynamic content (in most cases)
- The data provided needs to go through various Data Cleansing Techniques
- Resource intensive compared to highly automated tools
- Delays in delivery due to inaccuracies
- Restricted scalability
Pearson VUE, a leading education and publishing house, has 5000 centers in over 50 countries. They provide computer-based certification programs for Microsoft, Adobe, HP, etc. Pearson VUE had to analyze websites of these 5000 authorized test centers and also wanted to increase the exposure of their tests by finding relevant test centers to partner with. To achieve this, they had to go through thousands of websites, with multiple web pages and different structures.
In this case, it became obligatory to employ automated web scraping techniques. By doing so, Pearson VUE got the ability to assimilate, organize and transform data into real-time insights and make their business development process formal, accurate and sustainable. Now, their resources were able to spend more time on analyzing and find out areas where specific tests need to be promoted based on the test centers own business.
When faced with similar web extraction requirements, companies are usually left with two options:
- They can go for a highly automated web scraping tool which uses Robotic Process Automation (RPA), Machine Learning (ML) or Artificial Intelligence(AI) or
- They can outsource the whole process to a Web Scraping Service providers.
Advanced web scraping tools
Web scraping using RPA
Using software bots for web scraping instead of manual processes can help improve large scale scraping by streamlining extraction, automated data cleansing and continuously monitoring for updates /change in data source. Hence, Robotic Process Automation (RPA) can automate web data extraction enhancing performance, and simultaneously, reducing the resource time and cost.
Advantages of RPA:
- Eliminate manual processes
- Error-free information
- Cost-effective solution
- Better tracking of competitors and customers
- Quicker results
Disadvantages of RPA:
- Websites dealing with Captcha may require human intervention
- Maintenance cost
- Resource with programming and analytics knowledge is a must.
Web scraping using Machine Learning or AI
Machine Learning and AI are two separate technologies that have paved their way into the world of Web Scraping.
In Machine Learning, a user teaches the bot which information to extract and which to avoid. If we are extracting publishing dates of blogs from news websites, a user has to teach the bot what places to look at and what places not to. If any discrepancies occur, the bot will create a query that then will have to be solved by the user. The bot learns this and uses it for future reference.
JobsPikr, is an automated job discovery tool that fetches fresh job listings from companies around the globe. The sheer volume of webpages to be scraped made it mandatory for them to use Machine Learning to gather this vast pool of data.
In Artificial Intelligence (AI), the bot is given a loose set of rules based on which it extracts the information. The bot then keeps on learning and keeps creating new paths for itself. The more it is used the more it learns. In AI-based web data extraction, certain parameters are set known as the confidence score which determines whether the data extracted by the bot is accurate or not. If accurate, to what extent is it accurate? It is a kind of a basic reward system. This helps the bots learn more and improve each time it is used.
JobsPikr also provides a Job Matching software which uses Artificial Intelligence to match Jobs with relevant candidates. Although machines can’t work like humans, a certain level of the initial screening of candidates can be done using AI to reduce the workload of recruiters.
Advantages of ML/AI:
- High automation
- Least resource requirement
- Can access all sorts of dynamic content
- Faster and more accurate results
- Almost real time availability of information
Disadvantages of ML/AI:
- Still in its initial stages of development
- Expensive solution compared to other options available
Outsourced web scraping services
Many companies who need to scrape thousands of website and end up with huge volumes of data usually prefer to outsource this service to a web scraping service provider. A highly convenient option for most of the companies as they get access to valuable insights without going through any hassle of hiring resources, buying tools etc.
Moreover, the pros out-weight the cons with a huge margin, and hence, is usually the preferred option.
Advantages of outsourcing web scraping:
- High automation capabilities
- Cost-effective solution
- Data confidentiality managed as per the business requirement
- Scalability & flexibility
- Highly technical & experienced resources
Disadvantages of outsourcing web scraping:
- Co-ordination issues
Conclusion
We’ve gone through the many approaches you could take to web extraction and how you need to map the extraction technique to your specific business need and strengths. As a quick recap, answer these three basic questions before you zone in on your web scraping solution:
- What is the purpose of web extraction?
- What is the volume of data to be extracted?
- What level of time, money and resource investment is possible?
Given the critical
role of data in driving successful strategies, this is a choice to be made with
caution and care after having thoroughly evaluated your business requirements.
Having done that, you are well on your way to enhanced efficiencies and growth.