



A data lake is a central location in which to store all your data, regardless of its source or format. It is typically, although not always, built using Hadoop. The data can be structured or unstructured. You can then use a variety of storage and processing toolstypically tools in the extended Hadoop ecosystemto extract value quickly and inform key organizational decisions.
Because of the growing variety and volume of data, data lakes are an emerging and powerful architectural approach, especially as enterprises turn to mobile, cloud-based applications, and the Internet of Things (IoT) as right-time delivery mediums for big data.
Data Lake versus EDW
The differences between enterprise data warehouses (EDW) and data lakes are significant. An EDW is fed data from a broad variety of enterprise applications. Naturally, each applications data has its own schema, requiring the data to be transformed to conform to the EDWs own predefined schema. Designed to collect only data that is controlled for quality and conforming to an enterprise data model, the EDW is capable of answering only a limited number of questions.
Data lakes, on the other hand, are fed information in its native form. Little or no processing is performed for adapting the structure to an enterprise schema. The biggest advantage of data lakes is flexibility. By allowing the data to remain in its native format, a far greaterand timelierstream of data is available for analysis.
Some of the benefits of a data lake include:
- Ability to derive value from unlimited types of data
- Ability to store all types of structured and unstructured data in a data lake, from CRM data to social media posts
- More flexibilityyou dont have to have all the answers up front
- Ability to store raw datayou can refine it as your understanding and insight improves
- Unlimited ways to query the data
- Application of a variety of tools to gain insight into what the data means
- Elimination of data silos
- Democratized access to data via a single, unified view of data across the organization when using an effective data management platform
Key Attributes of a Data Lake
To be classified as a data lake, a big data repository should exhibit three key characteristics:
- A single shared repository of data, typically stored within Distributed File System (DFS). Hadoop data lakes preserve data in its original form and capture changes to data and contextual semantics throughout the data lifecycle. This approach is especially useful for compliance and internal auditing activities. This is an improvement over the traditional EDW, where if data has undergone transformations, aggregations and updates, it is challenging to piece data together when needed, and organizations struggle to determine the provenance of data.
- Includes orchestration and job scheduling capabilities (e.g., via YARN). Workload execution is a prerequisite for enterprise Hadoop and YARN provides resource management and a central platform to deliver consistent operations, security and data governance tools across Hadoop clusters, ensuring analytic workflows have access to the data and the computing power they require.
- Contains a set of applications or workflows to consume, process or act upon the data. Easy user access is one of the hallmarks of a data lake, due to the fact that organizations preserve the data in its original form. Whether structured, unstructured or semi-structured, data is loaded and stored as-is. Data owners can then consolidate customer, supplier and operations data, eliminating technicaland even politicalroadblocks to sharing data.
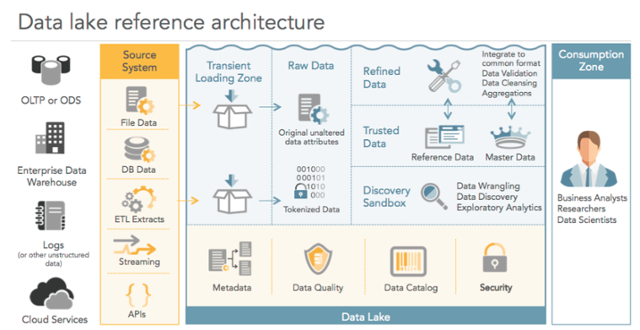

Image: Zaloni
Data lakes are becoming more and more central to enterprise data strategies. Data lakes best address todays data realities: much greater data volumes and varieties, higher expectations from users, and the rapid globalization of economies.